Sumarização Abstrativa com Google Pegasus?
Nesse tipo de sumarização, diferente do método já abordado, “TF-IDF”, no qual apenas extraímos as sentenças mais importantes do texto, iremos obter um resultado totalmente novo a partir do texto de entrada. Logo:
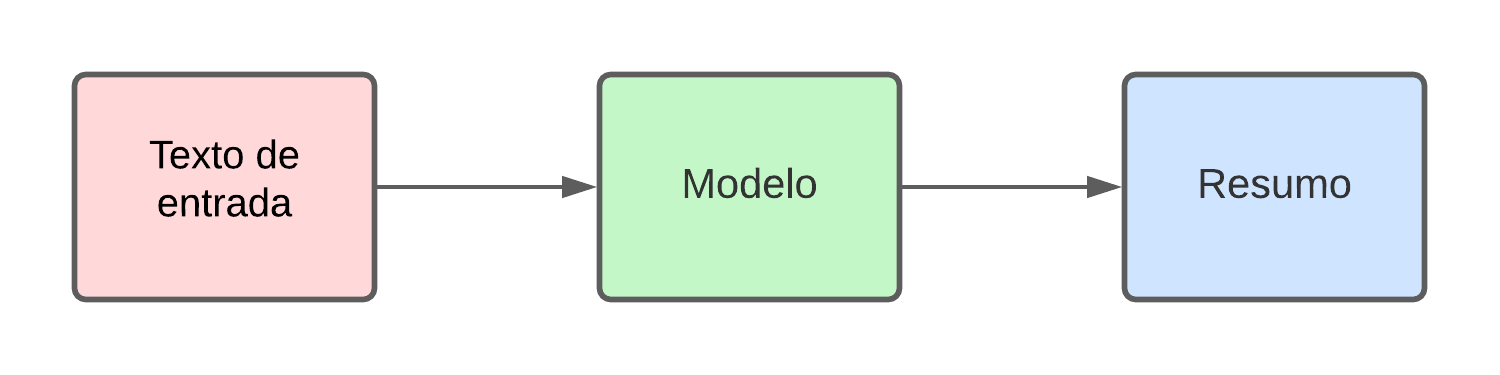
O objetivo é utilizar um modelo “Encoder-Decoder” (Codificador-Decodificador) que apresenta uma arquitetura sequencial (“Seq2Seq”) baseado em Redes Neurais Recorrentes (“RNN”), ou seja, o objetivo é converter uma sequência de palavras em outra sequência. Assim:

Para isso, o “Encoder” irá analisar o texto dado como input e irá gerar o que chamamos de “Context vector” (vetor de contexto) que é uma representação numérica do texto. Como por exemplo:

Ao passar os dados para o “Decoder” seu trabalho é decodificar o vetor de contexto de forma a produzir o resumo desejado.
Treinando o Modelo
Para que o modelo funcione adequadamente precisamos treiná-lo, mas para isso precisamos de muitos dados, são eles os textos e seus respectivos resumos. Para se ter uma idéia podemos ver a quantidade de dados necessários para treinar alguns modelos feitos pela Google:
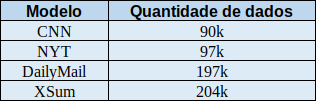
Seria uma tarefa impossível para nós encontrar tantos dados assim. Então aqui entra o “Google Pegasus”, que reúne diversos modelos pré-treinados com milhares de dados. Dessa forma, podemos utilizá-los e realizar apenas um ajuste fino para obter resultados com uma boa acurácia.
A hipótese explorada no artigo do Pegasus é que para obter esses dados necessários para treinar o modelo foi coletado diversos textos da internet (sites de notícias, reddit, blogs, etc) e a partir de uma métrica chamada “ROUGE” é possível criar um ranking das sentenças mais importantes do texto. Assim, é escolhida a sentença com maior ranking (muito similar a sumarização extrativa), e o grande diferencial é que ao coletar a sentença mais importante removemos a mesma do texto original. Assim, tal sentença representaria o resumo abstrativo gerado pelo algoritmo. Assim, o mesmo irá “aprender” a parafrasear e gerar sumarização abstrativa. Assim foram treinados os modelos disponibilizados pela Google, e podemos fazer um processo parecido para gerar os dados para o ajuste fino necessário para o modelo adequar bem as nossas necessidades. De acordo com o artigo, necessitamos de aproximadamente 1000 dados (textos e seus resumos) para tal tarefa, um número muito menor de dados comparando com o que seria necessário para treinar do zero um modelo. Por fim, para implementar o algoritmo temos o site Hugging Face que provê os modelos e suas documentações que facilita sua utilização.
Problemas
- É necessário traduzir o texto para o inglês e traduzir novamente para o português o resumo obtido;
- O Modelo gera resumos muito pequenos, mas é provável que isso possa ser ajustado.